Voor de Transformation Tuesday opdracht van december 2019 gingen we aan de slag met het maken van een eigen lieggrafiek. Doel hierbij is om bekend te raken met de verschillende trucs die toegepast worden om een lieggrafiek te creëren en op die manier zelf in staat te zijn om lieggrafieken te detecteren,
De opdracht was om je eigen lieggrafiek te maken, gebaseerd op data die je zelf wilt visualiseren. Het afkijken van bestaande voorbeelden is daarbij uiteraard een hele goede manier om te zien wat er allemaal mogelijk is.
De resultaten van de verschillende inzendingen zijn hieronder te vinden. Lijkt het je ook leuk om deel te nemen aan toekomstige Transformation Tuesday opdrachten? Meld je dan aan via onze website!
Joost
k ben de opdracht begonnen door op een rijtje te zetten wat je allemaal kunt doen om een lieggrafiek te maken. Daarbij kwam ik op de volgende punten:
- Spelen met de assen (x-as of y-as)
- Splitsen van assen om een conclusie te faken (y-as en z-as)
- Verkeerde datalabels gebruiken
- Verkeerde datapunten gebruiken
- Opzettelijk een ander soort meting kiezen (absolute aantallen i.p.v. relatieve aantallen)
- Zelf data toevoegen of erbij verzinnen
- Een optische illusie creëren (bijv. 3D effect)
- Verkeerde toelichting gebruiken (titels, annotaties, etc.)
- Overdrijven van een meting ten opzichte van andere metingen
Zo zijn er vast nog wel een aantal te bedenken, maar dit is wat er zo in mij op kwam. Vervolgens wilde ik zoveel mogelijk van deze effecten in 1 grafiek proberen te stoppen.
Omdat december een maand vol feestdagen is ben ik op zoek gegaan naar een passende dataset voor deze maand. Bij het CBS vond ik een tweetal artikelen over de omzet(stijging) van slijterijen in december: deze en deze. Met die data ben ik aan de slag gegaan.
De uitwerking ziet er als volgt uit:
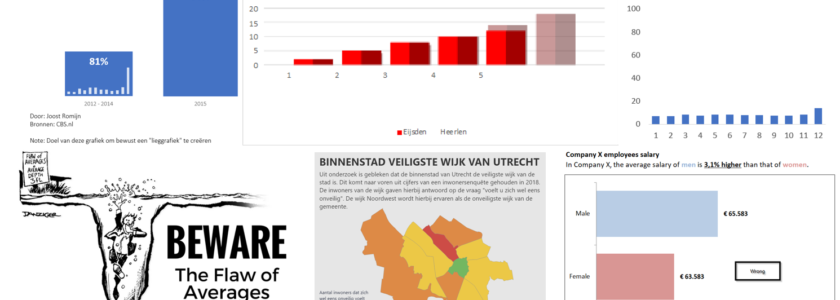
De liegeffecten in deze grafiek zijn als volgt:
- De omzetstijging in december in de jaren 2012-2014 zit niet in de dataset. Het artikel vermeldt alleen de omzetstijging van november en december tezamen. De stijging van december heb ik zelf herleid uit de data. Ik weet niet of dit klopt
- De x-as vergelijkt een reeks van 3 jaren (2012-2014) met 1 jaar (2015). Ik heb geen idee wat de cijfers van de individuele jaren ons zouden kunnen zeggen
- De y-as (niet zichtbaar) begint niet bij 0, waardoor het effect in 2015 veel groter lijkt
- De staaf van 2015 bevat een brede rand en is dus iets breder en hoger waardoor het effect in 2015 ook weer groter lijkt
- De titel heb ik zelf bedacht en is helemaal niet bewezen op basis van deze data
- De subtitel maakt niet echt duidelijk dat het een stijging betreft ten opzichte van de gemiddelde omzet van overige 11 maanden in het jaar
- Van de jaren 2012-2014 is het omzetaandeel per maand ten opzichte het jaartotaal toegevoegd als minichart. Deze y-as loopt niet van 0 tot 100 waardoor ook hier het effect van december weer overdreven wordt.
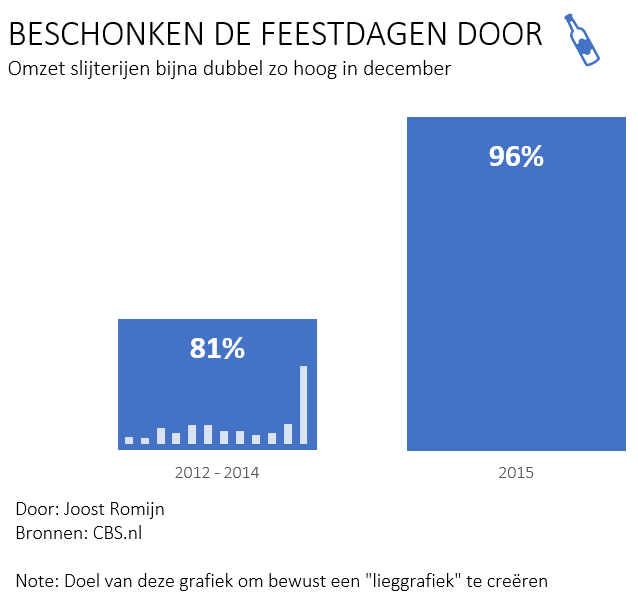
Wanneer je naar het omzetaandeel per maand zou kijken van de periode 2012-2014 op een schaal van 0 tot 100, dan zou deze er als volgt uit zien:
Dat geeft al heel ander beeld vind ik.
Leuk om eens een keer zelf hands-on aan de slag te zijn gegaan met een lieggrafiek. Ik heb hier weer een hoop van geleerd.
Wilbert
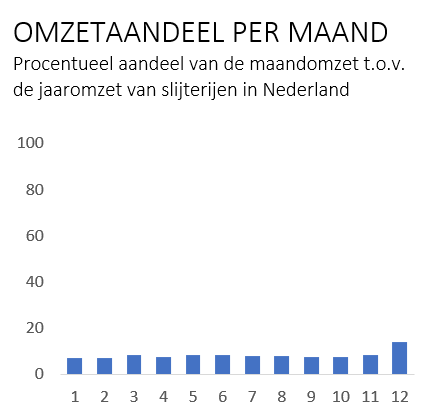
Onderstaand voorbeeld geeft het salaris gap tussen mannen en vrouwen aan van een fictief bedrijf. Deze laat zien dat mannen in Company X 3.1% meer verdienen dan vrouwen gemiddeld genomen. Vanuit eerste optiek kun je de conclusie trekken dat vrouwen in Company X minder verdienen dan mannen. Naast dat de grafiek (zie figuur 1 (wrong) & 2 right)) het gat visueel een stuk groter laat lijken dan het gat daadwerkelijk is is er nog een andere reden om kanttekeningen bij deze gegevens te plaatsen: het gemiddelde.
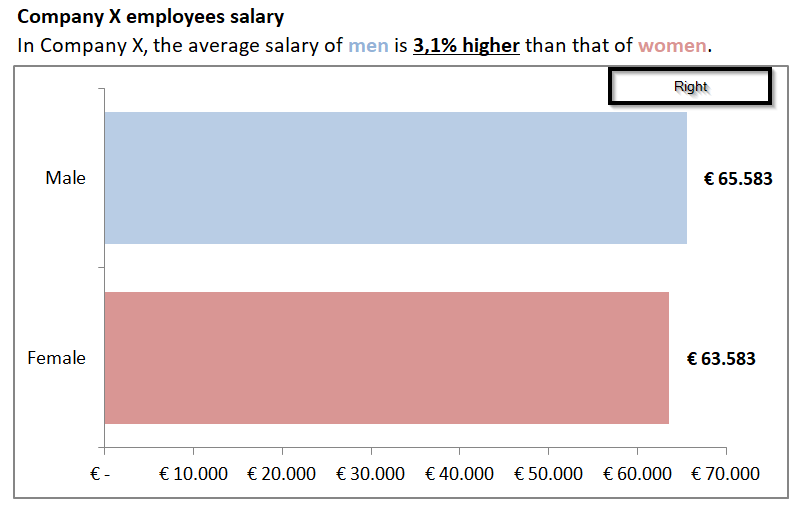
Figuur 1 & 2
In dit voorbeeld wordt gewerkt met het gemiddelde salaris van alle functies bij mannen en vrouwen in het fictieve bedrijf. Als we doorzoemen naar de onderliggende gegevens zien we een andere beeld (zie figuur 3). In onderstaande tabel zijn de functies en bijbehorende salarissen weergegeven tussen mannen en vrouwen. Hierin is duidelijk te zien dat bij junior functies de vrouwen meer verdienen dan de mannen als het gaat om de aantallen en de absolute waarde. Rekenkundig klopt het gemiddelde van alle salarissen en hiermee liegen we niet zo zeer, maar laten we ook niet het complete plaatje zien door enkel het gemiddelde te nemen over het totaal.
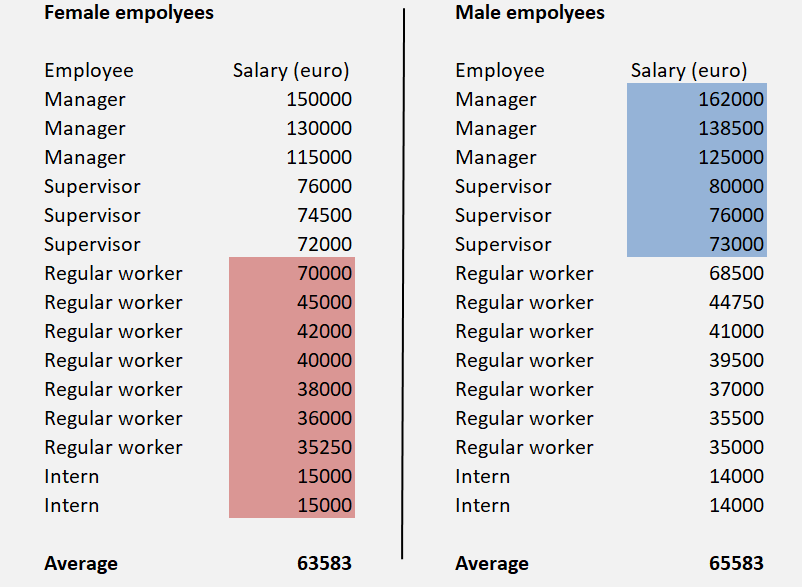
Figuur 3
Dit wordt ook wel de “flaw of averages” genoemd (link). Oftwel het misleidend effect van het gemiddelde. Een voorbeeld wordt gegeven door cartoonist Jeff Danziger waarbij een statisticus verdrinkt terwijl hij een rivier doorzeefde die gemiddeld slechts drie voet diep was. In het dagelijks leven zorgt de “flaw of averages” ervoor dat plannen op basis van de gemiddelde klantvraag, gemiddelde doorlooptijd, gemiddelde interest rate en andere onzekerheden, achter op schema en buiten het budget komen te liggen.

In het voorbeeld van Company X wordt ook het gemiddelde gebruikt op een verkeerde manier waardoor er eventueel verkeerde conclusies worden getrokken en nog erger, verkeerde bedrijfsbeslissingen. Om de analyse wat meer inhoud te geven zou deze ook als volgt uitgewerkt kunnen worden.

Ype
Sinds een paar jaar schaak ik ongeveer 5 keer per jaar met drie vrienden. Op een schaakavond speelt iedereen 3 keer tegen een wisselende tegenstander. Als je wint krijg je 1 punt, als je verliest 0 punten en bij een gelijkspel (remise) 0,5 punten. Als je alles wint kun je dus 3 punten per avond winnen.
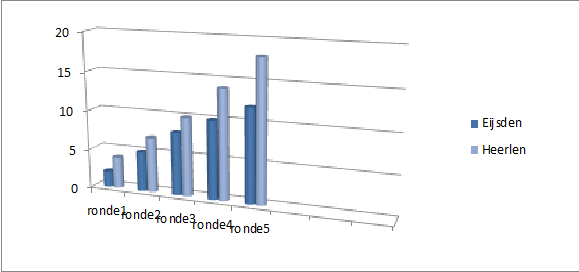
Naast een individueel klassement is er ook een competitie tussen Eijsden en Heerlen. In beide plaatsen zijn 2 van de 4 spelers woonachtig. Als woonplaats zijn er maximaal 5 punten te verdienen.
Ieder ‘seizoen’ worden er 8 schaakavonden georganiseerd. In onderstaande grafiek is een tussenstand te zien van het nu lopende seizoen.
Eijsden en Heerlen lijken gelijk op te gaan. Bij ronde 5 lijkt Heerlen licht op voorsprong te komen. En er lijkt een tussenstand van ronde 6 in de maak te zijn, waarbij de punten van Heerlen al bekend zijn.
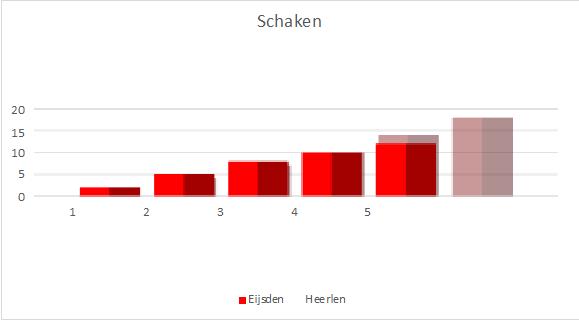
De bovenstaande grafiek is gemaakt in Excel en is in 3D weergegeven. Er is echter behoorlijk geroteerd en gekanteld, waardoor Eijsden gunstiger in beeld is gebracht. Bovendien is Eijsden in een heldere kleur weergegeven, terwijl Heerlen wat op de achtergrond blijft met een lichtere kleur. Ook “letterlijk” is Heerlen op de achtergrond gezet.
De werkelijke punten (van 5 schaakavonden) staan hieronder. Heerlen staat er een stuk gunstiger voor dan Eijsden.
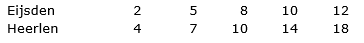
Als je dit op een realistischere manier zou weergeven, dan zou bijvoorbeeld onderstaande grafiek ontstaan:
Dennis
Ik heb me laten inspireren door de snelheidsmeters die Microsoft gebruikt om de performance van hun browser aan te tonen. Hetgeen ik heb gemaakt ziet er als volgt uit:

Wat ik in deze visualisatie heb gedaan is de cijfers tot uitdrukking laten komen in absolute aantallen in plaats van procentuele cijfers. Hierdoor scoren wijken met een hoog aantal inwoners standaard hoger dan de kleinere wijken. Het doel dat ik daarbij had was om het centrum van Utrecht het beste te laten scoren, daarom heb ik ook gespeeld met de legenda. De uitkomst spreekt voor zich!
Lijkt het je ook leuk om deel te nemen aan toekomstige Transformation Tuesday opdrachten? Meld je dan hieronder aan!
ua04xc
8pky3g
2wfat9
sgo68v
5ko78y