Click here to read this post in English
Net als vorige maand deed ik ook deze maand weer mee aan de #SWDChallenge van Storytelling With Data. Deze maand gingen we aan de slag met de visualisatie van onzekerheid in data.
Wanneer we data presenteren, wordt dit vaak gepresenteerd of geïnterpreteerd als “waarheid”. Data is echter zelden perfect. En de dingen die we er mee doen even min zo. We proberen met het visualiseren van data een zo goed mogelijk beeld van de werkelijkheid te creëren zonder ons publiek te misleiden. Maar soms heb je te maken met een incomplete dataset of een steekproef, maken we een voorspelling van de toekomst, of presenteren we gemiddelden zonder een beeld te verschaffen van de variantie. Hoe zorgen we er dan voor dat we zo’n goed mogelijk beeld van de werkelijkheid verschaffen?
In de praktijk heb ik wel eens te maken gehad met het visualiseren van data met een redelijke mate van onzekerheid. Ik worstelde dan nogal met de manier van presentatie. Meestal was ik niet echt tevreden met het eindresultaat, omdat mijn weergave dan niet echt een duidelijk beeld gaf van deze onzekerheid. De getallen werden dan vaak als waarheid geïnterpreteerd, waar het meer als een indicatie moest dienen. Door deze #SWDChallenge werd ik getriggered om hier eens wat meer tijd aan te besteden.
Voorbeelden
In mijn zoektocht naar inspiratie kwam ik een paar goede voorbeelden tegen. Bijvoorbeeld:
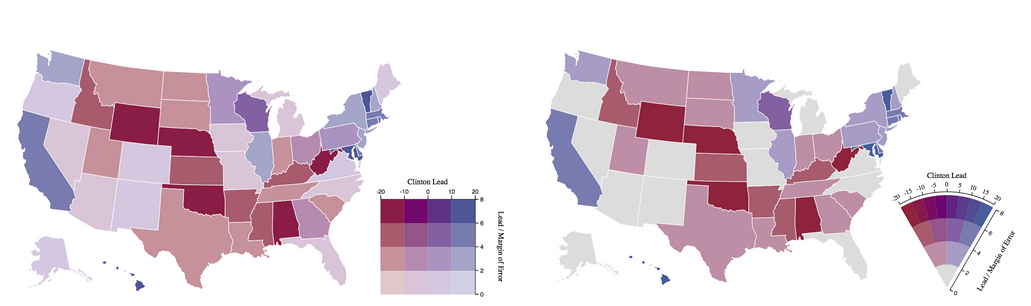
Een kleurenpallet van onzekerheid, waarbij de kleuren grijzer worden naarmate de foutmarge in de data toeneemt:
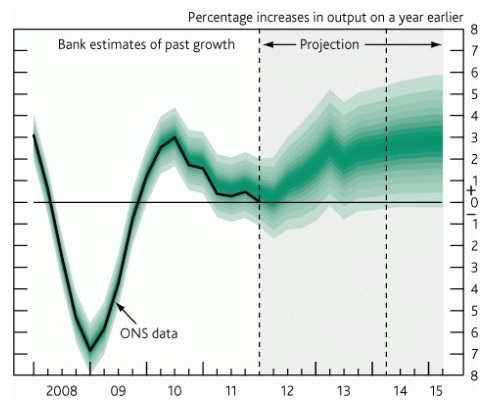
Een lijngrafiek met een forecast, waarbij de forecast een heel gebied omvat in plaats van één lijn.
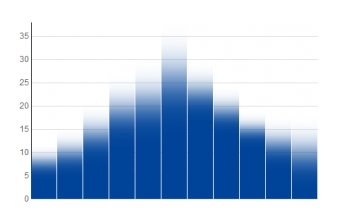
Of deze staafgrafiek met een kleurovergang, omdat de absolute waarde onzeker is.
Vooral het voorbeeld van de lijngrafiek vind ik een goede visualisatie, omdat ik hier in de praktijk een aantal keer tegen aan ben gelopen. Bijvoorbeeld wanneer ik lijngrafiek moest tonen van het gemiddelde van een reeks waarnemingen, door de tijd heen. Dan visualiseerde ik soms gewoon een lijngrafiek. In één scenario gebruikte ik boxplots per periode om toch de spreiding van de data te kunnen zien. Maar ik had ook voor een grafiek kunnen kiezen die lijkt op bovengenoemd voorbeeld. Een grafiek waarbij het gemiddelde of het middelpunt van de data als lijngrafiek wordt getoond, maar de spreiding ook zichtbaar is in de lijngrafiek. Daarom besloot ik om voor deze #SWDChallenge een dergelijk voorbeeld te creëren in Power BI.
Resultaat
Ik kon zo even geen goede anonieme of openbare dataset bedenken die aansloot bij mijn gedachtegang. Daarom heb ik zelf een fictieve case gemaakt met wat gegenereerde data in Excel.
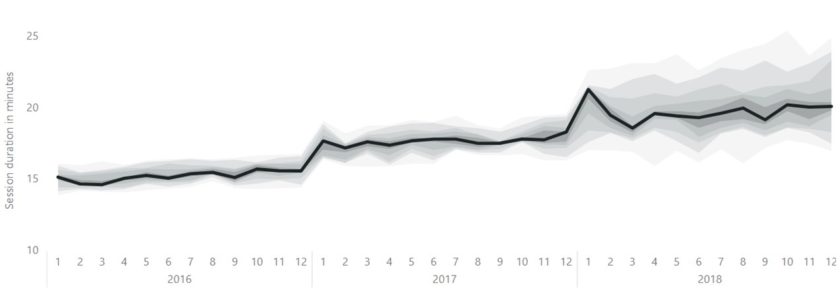
Hieronder zie je de sessieduur van een webshop. Oftewel, de tijd die bezoekers of klanten besteden op de website. Je ziet hier dat de spreiding van de sessieduur klein is. Deze ligt steeds rond de 15 minuten in 2016 en in 2017 (wat een toeval?!). Maar in 2018 neemt de spreiding (en dus de onzekerheid) van de sessieduur toe. Dat kan worden verklaard door de uitrol van het nieuwe design van de webshop in januari 2018.
Wat je hier eigenlijk ziet is een gestapelde areachart. De spreiding van de waarnemingen is opgeknipt in 10 stukken per maand. Ieder deciel is dus een “measure” in deze grafiek. De eerste measure (de minimum waarde) is onzichtbaar gemaakt door deze wit te kleuren. Iedere measure is het verschil van het deciel ten opzichte van het vorige deciel, omdat het een gestapelde grafiek betreft. Deze aanpak geeft wel een vreemd resultaat in de tooltip. Daarom heb ik een aangepaste tooltip gemaakt die de spreiding van de betreffende periode ook in een boxplot toont.
Ik heb deze visualisatie nu gemaakt met Power BI. Maar dit resultaat kun je denk ik op eenzelfde manier bereiken met andere BI tools, zoals QlikView, Qlik Sense, Tableau of Excel. De meeste BI tools bieden namelijk wel een gestapelde areachart aan als standaard grafiektype.
Mooi dat ik dit toch eens heb uitgewerkt naar aanleiding van deze #SWDChallenge. Ik hoop deze grafiek binnenkort ook eens in de praktijk toe te kunnen passen!
Wat zijn jouw ervaringen met het visualiseren van onzekerheid? Laat een berichtje achter of mail ons via info@datadump.nl!
Joost Romijn is BI Consultant bij ProAnalytics. Vanuit deze rol helpt hij organisaties met het vertalen van data naar bruikbare inzichten.
Eén reactie