
We leven in een tijd waarin het belangrijk is om te blijven leren. Dit is ook één van de redenen waarom we het initiatief van Transformation Tuesday zijn gestart. Met dit platform hopen we een veilige omgeving te creëren om creatief aan de slag te gaan met datavisualisatie. Je hebt immers geen opdrachtgevers die allerlei eisen stellen, je hebt een aantal weken de tijd om in eigen tempo iets op te leveren, krijgt feedback waarmee je je verder kunt ontwikkelen en kunt van andere deelnemers leren.
Dit leren gebeurt tegenwoordig steeds vaker via het internet met online cursussen, MOOCs en tutorials. Dit was een aantal jaren geleden wel anders, toen ging je voor het opdoen van kennis primair naar de bibliotheek. Ondanks deze verandering zijn bibliotheken nog steeds springlevend. Met een omzet van iets meer dan een half miljard euro in 2016 gebeurt er nog genoeg in deze sector om duidelijk te maken dat hier nog leven in zit. Daarom deze maand een dataset met ruim 10 jaar historische informatie over het wel en wee van de Nederlandse bibliotheken.
Voor de opdracht van deze maand ontvingen de deelnemers een bestand met daarin een aantal geselecteerde onderwerpen zoals het aantal uitgeleende boeken, de inkomsten en het aantal leden.
De inzendingen van de deelnemers zijn hieronder te bekijken.
Lijkt het je ook leuk om deel te nemen aan toekomstige Transformation Tuesday opdrachten? Meld je dan aan via onze website!
Joost
Het leuke aspect aan de Transformation Tuesday opdrachten vind ik dat je iedere keer met data aan de slag kan op een andere manier dan dat je in je dagelijkse werkzaamheden zou doen. Dit triggert de creativiteit en het leren van nieuwe dingen door verder te kijken dan standaard visualisaties in de BI tools die we iedere dag gebruiken.
Ik moet toegeven dat het deze maand niet van harte ging om iets nieuws te vinden. Ik twijfelde tussen een nieuwe grafiekvorm, een statistische onderbouwing van een conclusie of iets van een web mashup. Uiteindelijk heb ik er voor gekozen om mijn conclusies van de data te visualiseren met Qlik Sense Cloud. Omdat ik dit in mijn dagelijkse werkzaamheden (nog) weinig gebruik, blijf ik hiermee ook bij in de ontwikkelingen die plaatsvinden binnen dit platform. Het leek me leuk om een soort web mashup te maken met de objecten uit mijn Qlik Cloud app, maar daar kwam ik helaas niet heel ver mee. Toch was het weer leuk om de nieuwe features te ervaren in Qlik Sense.
Omdat we in de setting van Transformation Tuesday veel werken met explanatory data heb ik gekozen om mijn conclusies te vatten in een Qlik Sense story, in plaats van een interactief dashboard. Ook iets wat ik zelf niet zo snel zou gebruiken in mijn werkzaamheden.
Ik zag daarbij bijvoorbeeld de volgende nieuwe zaken ten opzichte van mijn laatste ervaringen met Qlik Sense:
- De expression editor is uitgebreid waardoor het nu veel makkelijker is voor eindgebruikers om Set Analysis syntaxen te maken of variabelen te gebruiken met behulp van de wizard
- De algemene look en feel is in mijn optiek verbeterd en vereenvoudigd
- Er zijn nieuwe grafiekvormen toegevoegd, zoals de boxplot, histogram, distribution plot en de waterfall chart (die ik ook in mijn visualisatie heb gebruikt)
- Er kunnen nu andere thema’s worden gekozen
- Qlik Sense doet zelf suggesties voor visualisaties o.b.v. de ingeladen data
- Het dashboard grid kan worden aangepast
- Tabellen zijn scrollbaar
- Dashboards zijn scrollbaar (naar beneden toe)
- De gegevensbeheer wizard biedt opties voor datatransformatie
- Grafiek-, dimensie-/expressielabels kunnen nu dynamisch worden gemaakt
- Alternate states zijn toegevoegd
- Gridlijnen in grafieken kunnen worden weggehaald
Iets wat ik nog miste bij het maken van mijn visualisatie:
- Een lineaire regressie trendlijn toevoegen is nog niet standaard mogelijk
- De hoogste en laagste waarde van een grafiek kunnen niet tegelijkertijd worden gehighlight in een story
Wilbert
In principe was dit niet mijn oorspronkelijk idee. Ik had namelijk al snel een andere dataset gevonden over public libraries in de US. Echter was deze qua omvang en detail vele malen groter dan de huidige dataset van Nederland. Mijn doel was om een vergelijking te maken over de jaren heen tussen US & NL. Echter kon ik geen duidelijke match vinden tussen deze twee datasets.
Het alternatief zien jullie hieronder.
Ik heb hier een poging gedaan om te oefenen met storytelling/infographic, maar het is niet echt een story geworden! Dit vraagt meer tijd en aandacht.
Dennis

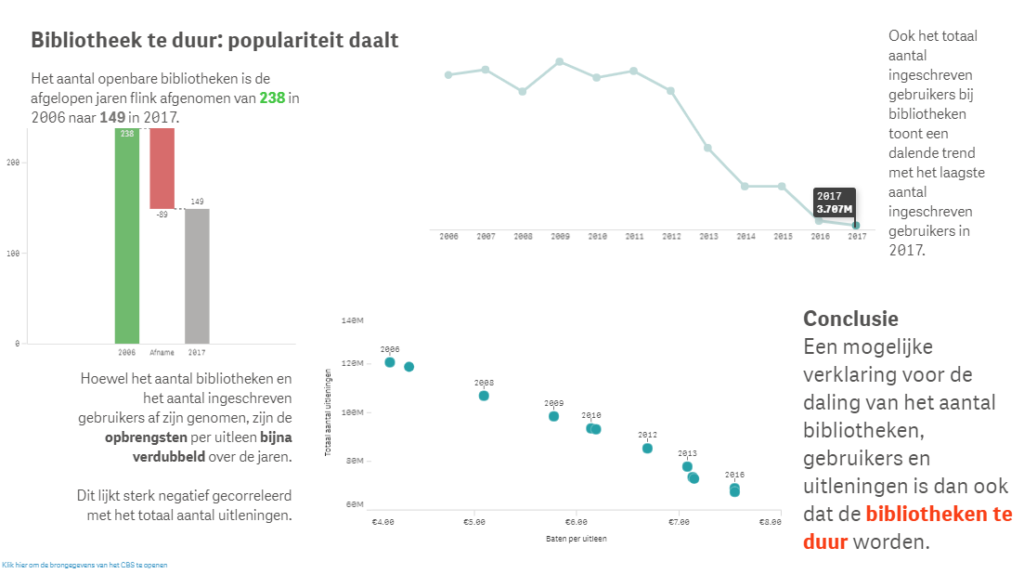
Een aantal Transformation Tuesday’s geleden hadden we nog een opdracht rondom een infographic. Daar heb ik toen niet aan mee kunnen doen en ik vond dat al direct jammer. Daarom heb ik de opdracht van deze maand aangegrepen om een eigen infographic te maken met daarin diverse analyses rondom de bibliotheek data.
Ik heb veel plezier beleefd bij het maken van deze infographic. Waar ik normaal veel tijd kwijt ben met het zoeken naar een conclusie/uniek inzicht in de data heb ik me nu kunnen richten op de vormgeving. Daarbij leek het toepasselijk om het resultaat te presenteren in de vorm van een boek. Omdat mijn uitgangspunt een pagina was met de verhouding van een A4-pagina heb ik ervoor gekozen om de resultaten op één pagina van het boek te tonen. Waar ik me bij veel infographics stoor aan de grote hoeveelheid kleuren die is gebruikt, heb ik ervoor gekozen slechts één kleur te gebruiken. Op die manier komt de focus nergens nadrukkelijk op te liggen. Als ik de nadruk ergens op wilde leggen dan zijn dat wel de titels (die de conclusies bevatten) en de bijbehorende cijfers die deze conclusie onderbouwen (groot weergegeven in iedere visualisatie). Bij het maken van de visualisaties heb ik een aantal keuzes gemaakt:
- De jaarnotatie teruggebracht van 2016 naar ’06 om een herhaling van getallen te voorkomen
- Horizontale en verticale lijnen niet zichtbaar gemaakt
- De cijfers in de teksten dik gedrukt weergegeven omdat deze ook een onderbouwing van de titels zijn
- In de tekst nadrukkelijk opgenomen dat de gebruikte cijfers een aantal nuaces bevat (het jaar 2017 is een voorlopig jaar en het aantal bibliotheken zijn organisaties, niet vestigingen)
- In de analyses de nadruk gelegd op de verschillen tussen 2006 en 2017
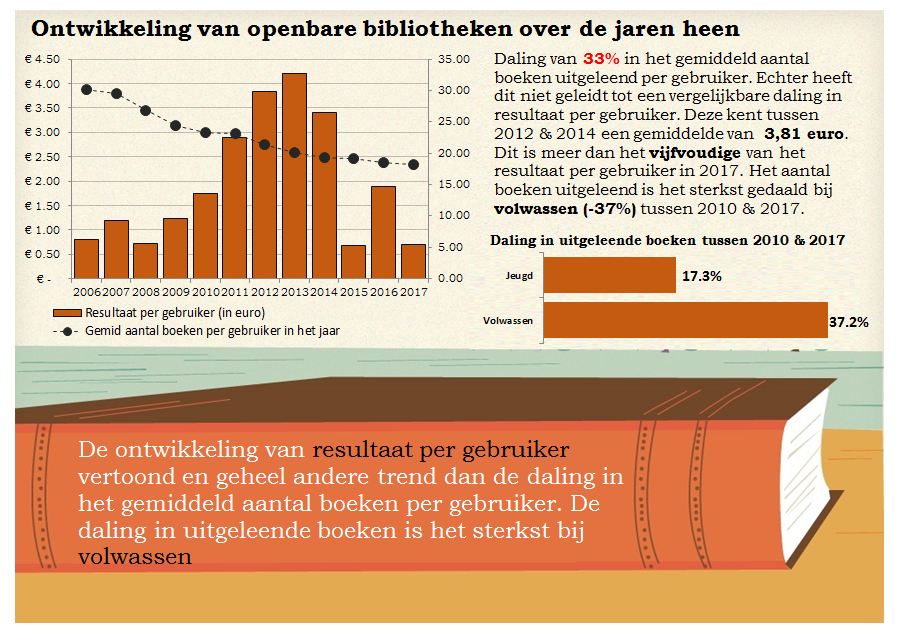
Een aantal dagen later heb ik nog een tweede versie gemaakt van mijn visualisaties met daarin een aantal verbeteringen:
- De vergelijking van bedragen tussen 2006 en 2017 gecorrigeerd na inflatie
- Het wegvallende label van 2017 gecorrigeerd in de lijngrafiek
- De tekst aan beide kanten uitgelijnd
Het geheel is gemaakt in een combinatie van Power BI en PowerPoint.
Leuk! Ik heb nog een leuk appje die alle exchange rates vanuit de ECB API’s inleest, inclusief visualisaties (en output CSV/qvd) natuurlijk. Handig, met name omdat het mag worden gebruikt voor alle officiële financiële cijfers (accountant proof).
Als je interesse hebt, stuur me een e-mailadres.
Hi Joost,
Klinkt goed! Je kunt ons bereiken via info@datadump.nl.
Groeten,
(ook) Joost